



Fighting Cyber Threats with Fuzzy Hashing
Employing Creativity in Cybersecurity
Visit the Evidence Files Facebook and YouTube pages, including the latest podcast episode; Like, Follow, Subscribe or Share!; Like, Follow, Subscribe or Share!
***Note: this article discusses cyberattack techniques and links to tools that malicious actors could use to commit crimes. These tools are linked because while they can be used for evil, they are also used by professionals working to prevent attacks and the harms that result from them. These are publicly available resources. I take no responsibility for anyone who may choose to use them illegally. For those with the proper intent, please make sure the access to or use of such tools does not violate any laws in the jurisdiction in which you live or work.***
Malware is so ubiquitous across our increasingly-connected world that legions of people now spend their entire days trying to find it. In addition to searching for malicious programs, threat hunters also work to identify their creators or users. Because attackers tend to try to cover their tracks, analysts often start with only bits of information (both literal and figurative) from which they engage in a sort of detective work to piece together clues to reach a positive identification. While analysts who are particularly skilled at what they do will employ numerous methodologies, this article discusses one in particular—hashing. I chose this topic because in one of my own cybersecurity classes, I discovered that students did not fully comprehend the variety of ways hashing can assist in cybersecurity and malware analysis. In part, this article is for them.
Hashing Basics
Cryptographic hashing, put simply, is a mathematical process for converting data into a unique string of letters and numbers. The algorithm used in the conversion determines the length of the output string. In other words, a specific hashing algorithm will always produce the same-sized output string regardless of the amount of content hashed. Hashable data includes essentially anything—letters, numbers, and other characters. Likewise, the file type makes no difference. One can calculate a hash value for a document, video, audio recording, or whatever else. To produce fixed-length outputs, the hashing process first breaks the target data into blocks. It then calculates the hash value of each block, combining them one-to-the-next until it reaches the end of the dataset. The key aspect of hashing lies in its consistency—identical data will produce an identical result every time if hashed using the same hash function.
For example, using the SHA-11 hash function, the word hello produces a value of:
AAF4C61DDCC5E8A2DABEDE0F3B482CD9AEA9434D
The result will remain the same irrespective of the tool used (at least it should if the tool is calibrated correctly), as long as the same function is applied. SHA-1 creates a 160-bit output value, displayed above and below. Any other input of any size run through the SHA-1 hash function will still produce an output of 160 bits. Here is an example:
8749A92A9941F1DD4815F10CC4A72197AB4E79C6
This value represents the SHA-1 hash result for the entire first paragraph of this article. Note that both outputs are 40 characters long. Within the output, each pair of characters represents a byte of data, articulated in hexadecimal.
The obvious value of cryptographic hashing is that it will reveal whether two large datasets are identical. The change of even a single bit will radically alter the hash value. To display this, here is the SHA-1 hash value output of the entire first paragraph again, but this time without the last period (the dot after ‘for them’).
572831FA493002910C6F6929CB46CD9EBD7893F6
As this example shows, the output changes considerably with even the smallest alteration from one dataset to the next. Thus, if two very large files are exactly the same, their hash value output will also be the same. This makes the comparison of two large datasets or files extremely fast. The illustration of the hash of the first paragraph with and then without a single period reveals, however, that two very large files need only one character—any character—to differ, and the hash value outputs will differ substantially. For analysts, this complicates matters when examining malware for telltale signs because attackers need only to tweak their code a tiny bit to evade a cryptographic hash analysis.
So How Can Malware Analysts Utilize Hashing?
In opening, this article noted that investigations of breaches and other malware-related incidents often start with limited data—or clues. Analysts, like any crime solver, seek to answer rather basic questions: what happened, how did it happen, when did it happen, why (or with what) did it happen, and who did it? The answer to many of these often begins by identifying the tool employed in the attack—the malicious program or file. Knowing the program used, analysts have an easier time figuring out the remaining questions because that knowledge directs them where to look. For instance, identifying known malware on a system might uncover the person or entity behind the attack if that person ‘took credit’ for a previous attack using the same program, or had been busted by authorities for using it before. In other cases, positively identifying malware on a system will enable analysts to profit from the research of others to determine what the program does or how to remove it. Moreover, identifying malware and employing a hash analysis allows analysts to search for wherever else it might be available on the internet or dark web.
Cryptographic hashing will certainly help identify malware that is identical to known programs or files, but attackers try to evade capture by covering their tracks. They typically engage in various methods to conceal their code, its function, its identity, and their own identity. Some might obscure the code through flattening, adding dummy code, or similar methods. For a deeper explanation of this, click the article below about obfuscation. Others might layer code from other malicious programs into their own. An illustration of how attackers do this can be seen in the Microsoft Exchange vulnerabilities attacks. Truly clever attackers combine elements of both of these, through methods like those used in Obfuscated Empire. Lazier or less capable attackers might opt to use tools that perform many of these kinds of feats for them; an example is the Avet evasion tool. Whatever path the attacker chooses, employing virtually any of them will deplete any value gained from cryptographic hashing.

Fuzzy Hashing
That’s where fuzzy hashing enters the picture. Fuzzy hashing works by hashing the individual blocks, but without hashing the sum of them. Thus, identical blocks will produce identical sections of output value. Mesh Security showed this by hashing two emails. The content was identical within the emails except for the addressee. So, in one case the salutation was “Hi Luke” and the other “Hi Homer.” The output hashes using a fuzzy hasher, in this case ssdeep, were as follows:
XPEW4kzeFo2rZS+PwoM8snSYlKnVyzeFo2rZS+PwoMOyrUq:XcfkzeFocZS+PwJ84/KVyzeFocZS+Pwb
sEW4kzeFo2rZS+PwoM8shYKyKnrLNyzeFo2rZS+PwoMOyrUf8:bfkzeFocZS+PwJ8DKrLNyzeFocZS+PwZ
One can readily see the similarities (in bold). Ssdeep provides a percentage calculation of the similarity, in the above example, it is 85%. To an analyst, this means that two files of this level of similarity likely perform many of the same functions. In comparing an unknown file to known malware, if one file has been previously researched this would significantly help an analyst determine what is going on in the case involving the mystery program. In essence, the analyst relies on the findings of other experts to establish known pieces of the puzzle, and can turn much more attention toward the unknowns making their process more efficient. Turning back to the email example above, for a moment, Mesh Security noted that using fuzzy hashing in this instance enables analysts to identify phishing email. A business following this practice would first scan and fuzzy hash incoming emails. Then, Mesh Security wrote,
If the email is similar to a fuzzy hash, it indicates a very similar structure to something that has been seen before. Depending on the type of reported email, this can be an indicator that the threat actor has sent out unique emails to particular individuals.
If we are confident that the inbound email is in fact malicious and these similar emails are the same campaign, we can now automatically develop a ruleset to actively detect any similar emails in future.
Business email compromise is among the commonest ways businesses suffer breaches. Employing fuzzy hashing as a defense method provides a strong and effective strategy to reduce the possibility of successful phishing or spear-phishing attacks. Coupling this with proper training of employees to identify such assaults greatly enhances a company’s security.

Obsidian illustrated how fuzzy hashing provides an effective counter against Adversary-in-the-Middle (AiTM) attacks. An AiTM attack involves the assailant positioning him or herself between two or more networked devices. From there, the attacker forces communication between the user and network to route traffic through a system he or she controls. By doing so, the adversary can perform a variety of actions, including stealing credentials or other data.
A common use of AiTM attacks is through phishing websites. A phishing website is basically a spoofed version of a legitimate site by which a malicious actor hopes unwitting users will enter critical data, such as login credentials or banking information, or engage in other activity beneficial to the criminal. While there are many ways to easily identify such sites, many people still fall for them because attackers adopt tactics that require some attention to detail to notice. The fake website address (URL), for example, might read “m!crosoft.com” instead of “microsoft.com.” In other cases, the site will begin with http:// rather than https:// --note the (s). Oftentimes, when users reach these sites they receive a warning from their browser. A common alert appears like in the picture below. Browsers trigger this alert about potentially malicious activity because threat hunters flag such sites when discovered. They then record them in databases to which browsers refer when the user attempts to enter them. Unfortunately, bad actors create new ones all the time, so a browser will not always alert the user that he or she is about to enter a malicious site. To find these malicious sites, threat hunters use fuzzy hashing (among other tactics).
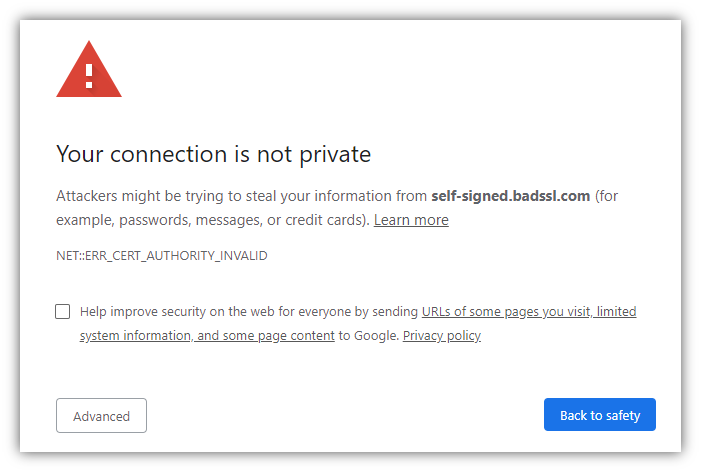
In the example provided by Obsidian, analysts directed their hashing efforts at the Document Object Model (DOM), rather than the HTML. They did so because hashing the HTML produces far too many similar results to be useful toward distinguishing between good and bad. Hashing the DOM and comparing it to known AiTM sites (in this case, EvilProxy/Tycoon sites) indicated the level of similarity. A DOM containing a high enough similarity percentage suggests that the analyzed site is probably a modified version of an EvilProxy/Tycoon site. But, this explanation requires more parsing.
Mozilla describes the DOM as follows:
[It] connects web pages to scripts or programming languages by representing the structure of a document—such as the HTML representing a web page—in memory. Usually it refers to JavaScript, even though modeling HTML, SVG, or XML documents as objects are not part of the core JavaScript language.
Attacks launched with EvilProxy/Tycoon (EPT) start with phishing attempts—emails sent to recipients with the hope that they will click on the link taking them to the attacker’s spoofed site. Although a person could arrive at the dangerous site directly, this is unlikely as these sites are rarely indexed, meaning the user would need to type in the faked URL. (Users may land on such a site by accident by mistyping the URL, but this also appears to be rare). In any event, the EPT redirects the victim several times to evade any potential detection measures the victim’s company’s security may utilize. When the victim finally arrives at the unsafe destination, EPT adds its own multifactor authentication to the user’s account, thereby giving the attacker legitimate credentials. This allows the attacker to infiltrate the network from which the user came (typically the user’s employer’s network), and operate with full privileges. Once the attacker accomplishes this, he or she can steal data, make changes to the network, conduct sabotage, or engage in other nefarious activity, irrespective of whether the user voluntarily submitted any data.
Running an automated DOM fuzzy hash would assist with identifying phishing sites prior to allowing employees to engage with them. Malicious site hashes are recorded and the lists are available to researchers and others who need them, allowing cybersecurity professionals to create automated comparative analyses. From these they can blacklist any site meeting a high enough comparison score. Trend Micro determined that a comparability rating of 9 produced only a 0.001% false positive rate. Therefore, establishing blacklists of positive hits would barely hinder legitimate company operations, if at all, but would vastly strengthen security.
Just as fuzzy hashing assists with identifying phishing schemes from various angles, it can do the same with specific malware files. A lot of the malicious software floating around the internet borrows certain functions from pre-existing programs. As mentioned above, the Microsoft Exchange vulnerabilities attack involved several processes adopted from older malware—all of which had been identified in the CVE database—and directed them in novel ways to exploit a new attack vector. Even if an assailant develops new processes to conduct an attack, it is easy and efficient to borrow previous methodologies and incorporate them into the new processes to create a more robust weaponized program. Doing so, however, means that a fuzzy hash analysis will indicate that the new program is probably malware. Put another way, discovering a program or file that contains a portion of known malware in its code suggests that the intent of this ‘new’ program or file is malevolent. Similarly to phishing detection, companies can set a comparative rating level that will trigger an alert giving its analysts the opportunity to quarantine and examine more closely any program or file before it can create any havoc in the network or system.
Conclusion
Cybersecurity professionals will perform their jobs at the highest caliber if they equip their toolboxes with a wide variety of resources. Hunting for and discovering malicious software requires creativity and flexibility because attackers go to great lengths to avoid detection. The resources available to attackers regularly change, but always seem to grow. Defenders must respond and adapt to this ever-changing environment with equal levels of aptitude and fury. Fuzzy hashing represents one such creative adaptation in the cybersecurity world.
***
I am a Certified Forensic Computer Examiner, Certified Crime Analyst, Certified Fraud Examiner, and Certified Financial Crimes Investigator with a Juris Doctor and a Master’s degree in history. I spent 10 years working in the New York State Division of Criminal Justice as Senior Analyst and Investigator. Today, I teach Cybersecurity, Ethical Hacking, and Digital Forensics at Softwarica College of IT and E-Commerce in Nepal. In addition, I offer training on Financial Crime Prevention and Investigation. I am also Vice President of Digi Technology in Nepal, for which I have also created its sister company in the USA, Digi Technology America, LLC. We provide technology solutions for businesses or individuals, including cybersecurity, all across the globe. I was a firefighter before I joined law enforcement and now I currently run a non-profit that uses mobile applications and other technologies to create Early Alert Systems for natural disasters for people living in remote or poor areas.
Find more about me on Instagram, Facebook, LinkedIn, or Mastodon. Or visit my EALS Global Foundation’s webpage page here.
Note that the SHA-1 and MD5 hash algorithms are now considered compromised and generally should not be used for cryptographic security. Nevertheless, they remain useful for identifying datasets and files and thus should not be ignored.
That was really the best ever explanation of how those things work and the tireless efforts the good guys most endure and keep on plucking away with it. It's a shame the Internet can't recognize all of it and shut down those criminals that make these harmful attacks.